はじめに #
モデルの性能を検証するとき、データを学習用と検証用に分割します。これは、未知のデータに対してもモデルの精度が良いこと(汎化性能)を評価するためです。より安定して汎化性能を評価するため、データの分割方法を何度も変えて評価します。これを交差検証 (cross validation) と呼びます。
交差検証にはいくつか種類がありますが、ここでは次の手法を説明します。
- k分割交差検証 (k-fold cross validation)
- 層化k分割交差検証 (stratified -)
また、この記事ではPythonとScikit-learnによるサンプルコードも示します。実行環境は以下の通りです。
- Python: 3.9.7
- NumPy: 1.20.3
- sklearn: 0.24.2
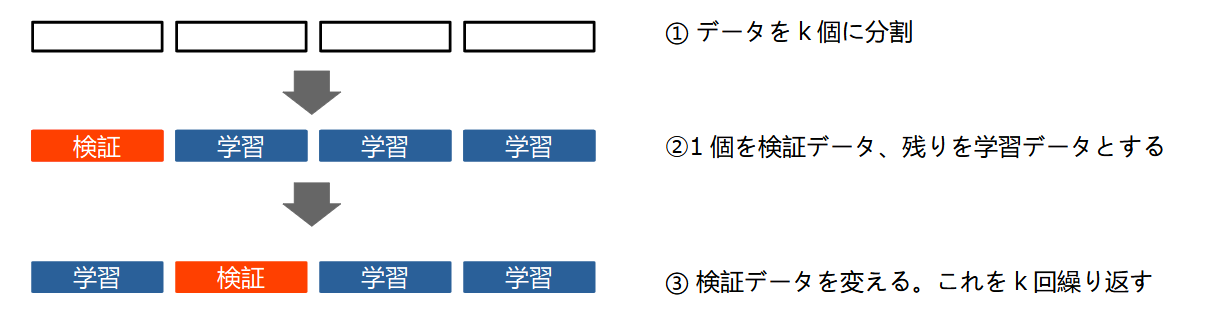
k分割交差検証 #
k分割交差検証では、データをk個のサブセットに等分割します(kの値は5~10程度にすることが多いです)。まず、この内の1個を検証データとして除き、残りのk-1個のデータでモデルを学習します。その後、検証データで精度などを評価します。次に、今度は別のサブセットを検証データとして、他のk-1個で学習・評価します。検証データを次々と変更し、これをk回繰り返します。最終的にk回分の評価結果(精度など)が得られることになります。なお、k分割交差検証の課題は、学習と検証をk回繰り返すため処理時間が掛かることです。
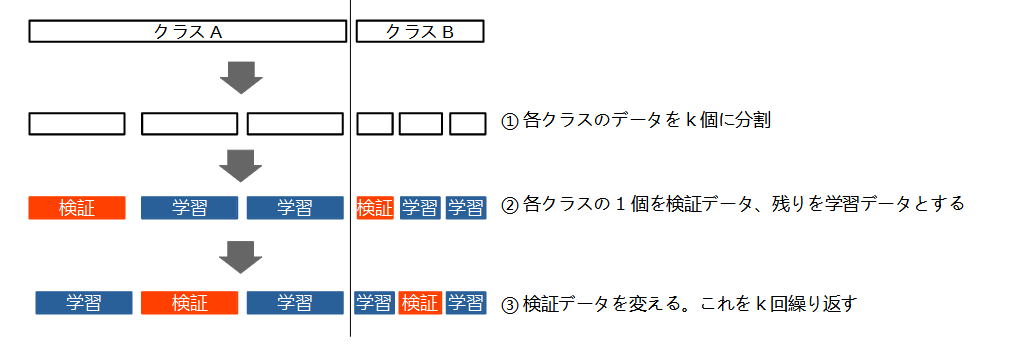
層化k分割交差検証 #
データに偏りがある場合、単純なk分割交差検証ではうまくモデルを評価できないことがあります。例えば、2クラス分類問題で、データの90%をクラスA, 残りの10%をクラスBが占める場合を考えます。このようなデータを適当に分割すると、あるサブセットにはクラスBが全く含まれていない、という可能性もあります。
層化k分割交差検証では、各クラスのデータをそれぞれk分割することによって、偏ったデータに対処できます。すなわち、各サブセット内のクラスの比率を、全体データにおける比率と等しくします。
scikit-learnの交差検証 #
KFoldクラスによるk分割交差検証 #
scikit-learnではsklearn.model_selection.KFoldというクラスにk分割交差検証が実装されています。
class sklearn.model_selection.KFold(n_splits=5, shuffle=False, random_state=None)主なパラメータの意味は以下の通りです。
n_splits(int): 分割するサブセットの数。デフォルト値は5(バージョン0.22より前は3)。shuffle(bool):Trueの場合、データをシャッフルする。デフォルト値はFalse.random_state(int):shuffle=Trueの場合、シャッフルするランダムシードを指定する。デフォルト値はNone(実行の度に結果が変わる)。
また、主なメソッドは以下の通りです。
split(X): 特徴量データX(行がサンプル、列が特徴量)に対し、学習データと検証データの各インデックスを返す。
KFoldクラスの使用例 #
KFoldクラスの使用例を示します。Xは行がサンプル、列が特徴量の説明変数です(PandasのDataFrameなどでも可)。Yは目的変数です。
まず、データをシャッフルしない場合の例を示します。
import numpy as np
from sklearn.model_selection import KFold
X = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
Y = np.array([10, 20, 30, 40, 50, 60])
kf = KFold(n_splits=3)
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "TEST:", test_index)実行結果
以下のように、学習データ (TRAIN) と検証データ (TEST) の各インデックスが得られます。分割数を3にしたため、ループ回数は3になっています。また、test_indexのデータはシャッフルされていない(順に得られている)ことが分かります。
TRAIN: [2 3 4 5] TEST: [0 1]
TRAIN: [0 1 4 5] TEST: [2 3]
TRAIN: [0 1 2 3] TEST: [4 5]次に、先ほどと同じデータに対し、シャッフルして分割します。
kf1 = KFold(n_splits=3, shuffle=True, random_state=0)
for train_index, test_index in kf1.split(X):
print("TRAIN:", train_index, "TEST:", test_index)実行結果
以下のように、学習データと検証データの順序がシャッフルされました。
TRAIN: [0 1 3 4] TEST: [2 5]
TRAIN: [0 2 4 5] TEST: [1 3]
TRAIN: [1 2 3 5] TEST: [0 4]StratifiedKFoldクラスによる層化k分割交差検証 #
scikit-learnではsklearn.model_selection.StratifiedKFoldというクラスに層化k分割交差検証が実装されています。基本的な使用方法はKFoldクラスと同じです。
class sklearn.model_selection.StratifiedKFold(n_splits=5,
shuffle=False, random_state=None)主なパラメータの意味は以下の通りです。
n_splits(int): 分割するサブセットの数。デフォルト値は5(バージョン0.22より前は3)。shuffle(bool):Trueの場合、データをシャッフルする。デフォルト値はFalse.random_state(int):shuffle=Trueの場合、シャッフルするランダムシードを指定する。デフォルト値はNone(実行の度に結果が変わる)。
また、主なメソッドは以下の通りです。
split(X, Y): 説明変数X(行がサンプル、列が特徴量)、目的変数Yに対し、Yの比率が均等になるような学習データと検証データの各インデックスを返す。
StratifiedKFoldクラスの使用例 #
StratifiedKFoldクラスの使用例を示します。Xは行がサンプル、列が特徴量の説明変数です(PandasのDataFrameなどでも可)。Yは目的変数であり、0または1の値を取ります(2クラス分類問題を想像してもらえればよいと思います)。Yの3分の2が0, 残りが1であり、不均衡なデータです。
まず、データをシャッフルしない場合の例を示します。
import numpy as np
from sklearn.model_selection import StratifiedKFold
X = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
Y = np.array([0, 0, 0, 0, 1, 1])
skf = StratifiedKFold(n_splits=2)
for train_index, test_index in skf.split(X, Y):
print("TRAIN:", train_index, "TEST:", test_index)実行結果
以下のように、学習データ (TRAIN) と検証データ (TEST) の各インデックスが得られます。分割数を2にしたため、ループ回数は2になっています。各ループのtest_indexには、Yの値が0となるインデックスが2個、1となるインデックスが1個含まれており、均等に分割されています。また、TESTはシャッフルされていない(順に得られている)ことが分かります。
TRAIN: [2 3 5] TEST: [0 1 4]
TRAIN: [0 1 4] TEST: [2 3 5]次に、先ほどと同じデータに対し、シャッフルして分割します。
skf1 = StratifiedKFold(n_splits=2, shuffle=True, random_state=0)
for train_index, test_index in skf1.split(X, Y):
print("TRAIN:", train_index, "TEST:", test_index)実行結果
以下のようにデータは均等に分割されたまま、学習データと検証データの順序がシャッフルされました。
TRAIN: [0 1 5] TEST: [2 3 4]
TRAIN: [2 3 4] TEST: [0 1 5]