はじめに #
サポートベクターマシン (SVM, support vector machine) は分類アルゴリズムの1つです。SVMは線形・非線形な分類のどちらも扱うことができます。また、構造が複雑な中規模以下のデータの分類に適しています。
線形SVM #
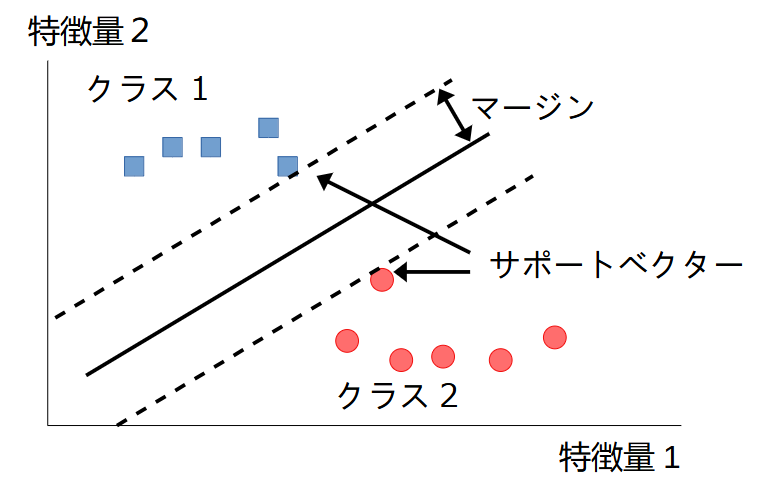
簡単な例として、画像のように2つのクラスを分類する問題を考えます。2つのクラスは直線で簡単に分類できます。これを線形分割可能 (linearly separable) といいます。グラフの実線は、SVM分類器の決定境界です。この境界は、マージン(最も近い学習データとの距離)が可能な限り大きくなるように設定します。この操作のことをマージン最大化と呼びます。また、最も近い学習データのことをサポートベクターと呼びます。
ソフトマージンとハードマージン #
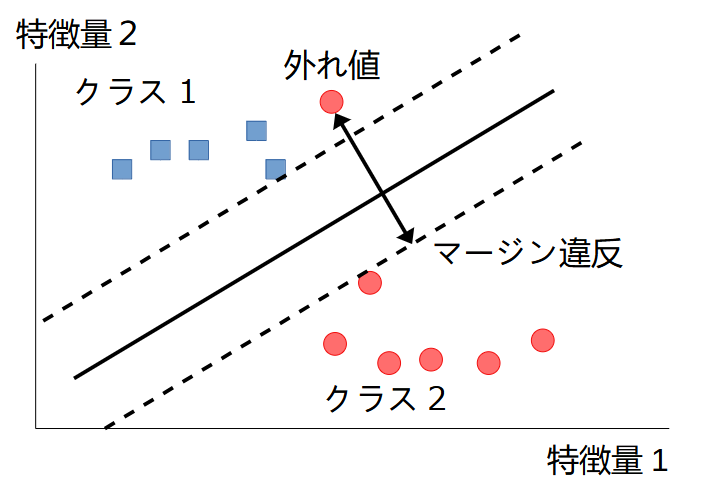
すべての学習データがマージンの外側の正しい側の領域にいなければならない場合、ハードマージン分類と呼ばれます。この場合、データは線形でなければならず、外れ値が存在すれば、モデルが大きく変わってしまう課題があります。
外れ値の課題を解決するため、マージンの内側に一部の学習データが入ることを許容する必要があります。これをソフトマージン分類といいます。ソフトマージン分類では、マージンをなるべく大きくし、かつマージン違反(マージンの内側にデータが入り込むこと)をなるべく減らすことのバランスを取ります。
非線形SVM #
実際のデータは、下のグラフのように線形分離できるとは限りません。このような場合、例えば既存の2つの特徴量から新たな特徴量を作って、3次元空間で線形分離することが考えられます。実際には、特徴量を2乗したり、異なる特徴量同士の積とったりして新たな特徴量の候補とし、その中から有用な特徴量を抽出します。この手法をカーネル法といいます。良く用いられるカーネルとして、多項式カーネルとガウスカーネルの2つがあります。
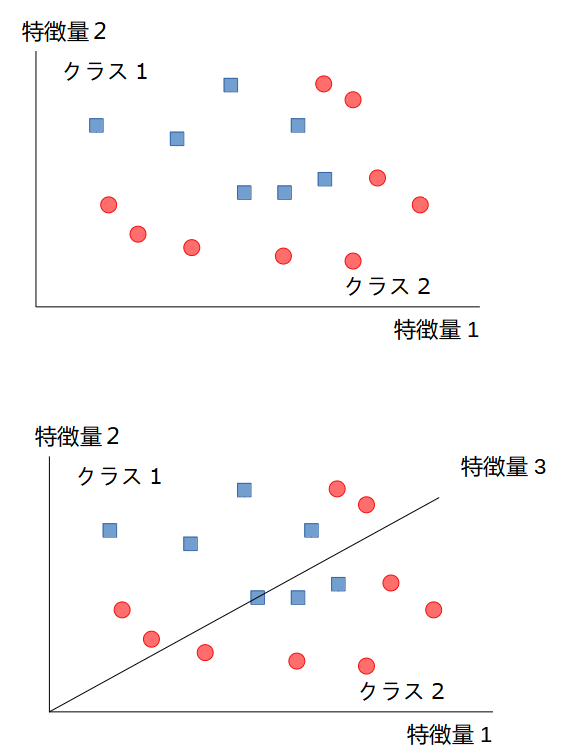
カーネル法では、次数が低いと有用な特徴量を見つけられなかったり、反対に次数が高過ぎると計算量が膨大になる短所があります。しかし、SVMの場合はカーネルトリック (kernel trick) という手法を使うことで、計算量を減らすことができます。
scikit-learnのSVM #
SVCクラス #
scikit-learnではsklearn.svm.SVCというクラスに分類のためのSVMが実装されています。
class sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='scale',
coef0=0.0, shrinking=True, probability=False, tol=0.001,
cache_size=200, class_weight=None, verbose=False, max_iter=- 1,
decision_function_shape='ovr', break_ties=False, random_state=None)
主なパラメータの意味は以下の通りです。
C(float): 正則化のパラメータ。値が小さいほど正則化が強くなります(デフォルトは1.0)。kernel(str): カーネルの種類。'rbf': ガウスカーネル(放射基底関数、Radial basis functionの略)、'linear': 線形、'poly': 多項式、'sigmoid': シグモイド関数(デフォルトは'rbf')。degree(int): 多項式カーネル ('poly') の次数(デフォルトは3)。他のカーネルでは無効。gamma({'scale','‘auto'} orfloat): ガウスカーネル ('rbf') とシグモイドカーネル ('sigmoid') の係数。'scale'のとき1/(n_features * X.var()).'‘auto'のとき1 /n_features(デフォルトは'scale')。probability(bool):Trueの場合、予測時に各クラスに属する確率を返す(デフォルトはFalse)。cache_size(float): キャッシュサイズ(単位:MB)(デフォルトは200)。random_state(intorNone):probability=Trueのときデータをシャッフルするためのランダムシード。同じ整数値を指定すれば、常に同じ予測結果が得られる。
また、主なメソッドは以下の通りです。
fit(X, y): 特徴量X, クラスyを教師データとして学習する。predict(X): 特徴量Xに対するクラスの予測結果を返す。predict_proba(X): 特徴量Xに対する各クラスの予測確率を返す。
使用例 #
SVCクラスの使用例を示します。実行環境は以下の通りです。
- Python: 3.9.7
- NumPy: 1.20.3
- sklearn: 0.24.2
X_trainは行がサンプル、列が特徴量の2次元配列です(PandasのDataFrameなどでも可)。y_trainは分類クラスの1次元配列です。次に、SVCクラスのオブジェクトをclfという名前で作成します(clfはclassifierから名付けています)。予測確率を返すようにするため、オプションでprobability=Trueと設定しています。
import numpy as np
from sklearn.svm import SVC
# 学習データ
X_train = np.array([[0, 1],
[1, 3],
[3, 2]])
y_train = np.array([0, 0, 1])
clf = SVC(probability=True)
fitメソッドで学習し、predictメソッドで予測します。予測結果は1次元配列となります。
# 学習
clf.fit(X_train, y_train)
X_test = np.array([[0, 1],
[2.8, 2]])
# 予測
y_pred = clf.predict(X_test)
print(y_pred)
実行結果
[0 1]
次に、predict_probaメソッドで予測確率を取得します。
y_prob = clf.predict_proba(X_test)
print(y_prob)
実行結果
[[0.33570931 0.66429069]
[0.86839708 0.13160292]]
1番目のデータ[0, 1]について、クラス0に属する確率は0.336, クラス1に属する確率は0.664であることを示しています。
