はじめに #
凝集型クラスタリング (agglomerative clustering) は、個々のデータ点をクラスタとして開始し、似ているクラスタ同士を1つずつ結合していくクラスタリング手法です。終了条件(残ったクラスタ数など)を満たすまでクラスタの結合を繰り返します。似ているクラスタを判定する尺度には、結合度 (linkage) を用います。結合度には以下のようなものがあります。
- ward: 結合したときにクラスタ内の分散 (variance) の増加が最小となるように2つのクラスタを選択。
- average: クラスタに含まれる点の平均距離が最小となるように2つのクラスタを選択。
- complete (maximum): 2つのクラスタの点間の距離の最大値が最小となるように2つのクラスタを選択。
- single: 2つのクラスタの点間の距離の最小値が最小となるように2つのクラスタを選択。
これらの中ではwardがよく用いられます。
この記事ではPythonとSciPyによるサンプルコードも示します。実行環境は以下の通りです。
- Python: 3.9.7
- NumPy: 1.20.3
- SciPy: 1.7.1
SciPyの凝集型クラスタリング #
linkageメソッド #
SciPyではscipy.cluster.hierarchy.linkageというメソッドに凝集型クラスタリングが実装されています(scikit-learnにも実装されていますが可視化機能がないため、SciPyを使用します)。
scipy.cluster.hierarchy.linkage(y, method='single',
metric='euclidean', optimal_ordering=False)
主なパラメータの意味は以下の通りです。
y(2D array): クラスタリングするデータmethod(str): = 結合度のアルゴリズムを指定。'single'(デフォルト),'complete','average','centroid','median','ward','weighted'を選択できる。metric(str): 距離の計算方法。'euclidean'(デフォルト),'mahalanobis','cosine'などを選択できる。optimal_ordering(bool):Trueにすると、葉の距離同士が最小になるように結果がソートされます。可視化時に有用な場合がありますが、計算が遅くなります(デフォルトはFalse)。
また、クラスタの階層を可視化するにはscipy.cluster.hierarchy.dendrogramというメソッドを用います。
使用例 #
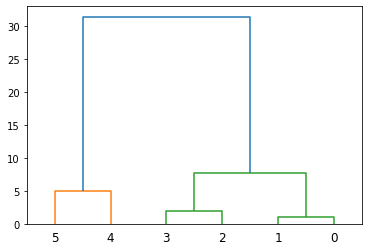
linkageメソッドの使用例を示します。簡単のため、1次元のデータを用います。
import numpy as np
from scipy.cluster.hierarchy import linkage, dendrogram
X = np.array([[0],[1],[5],[7],[20],[25]])
Z = linkage(X, 'ward', optimal_ordering=True)
dn = dendrogram(Z)
実行すると以下のグラフが出力されます。横軸の数字はデータのインデックスです。また、グラフの高さは結合するノード同士の距離を表しています。例えば、オレンジの部分は4, 5番目のデータ(20と25)の距離が5であることを示します。