はじめに #
前回の記事で、ChainerのChainクラスとOptimizerを使って最小限のニューラルネットワーク (NN) を実装した。今回は、データセットから学習用ミニバッチを作成してくれるIteratorクラスの動作を確認する。
環境 #
| ソフトウェア | バージョン |
|---|---|
| Spyder | 3.2.8 |
| Python | 3.6.5 |
| NumPy | 1.14.3 |
| Chainer | 4.2.0 |
以下では、各ライブラリを以下のようにインポートしていることを前提とする。
import numpy as np
import matplotlib.pyplot as plt
import chainer
import chainer.links as L
import chainer.functions as F
from chainer import optimizers, Chain, dataset, datasets, iterators
import matplotlib.pyplot as pltIteratorクラス #
Iteratorクラスは、データセットの説明変数と目的変数を束ねたミニバッチ作成や、データ順序のシャッフルを行ってくれるクラスである。Chainer 4.2.0では以下3つのIteratorが利用可能である。
| クラス | 説明 |
|---|---|
| SerialIterator | 最も単純なIterator |
| MultiprocessIterator | multiprocessingモジュールにより並列化 |
| MultithreadIterator | threadingモジュールにより並列化 |
本記事ではSerialIteratorクラスを扱う。
chainer.iterators.SerialIterator(dataset, batch_size,
repeat=True, shuffle=True)パラメータの説明は以下の通り。
dataset: 反復させるデータセット。
batch_size: int型 各ミニバッチのサンプル数。
repeat: bool型
Trueの場合、無限に反復させる。
Falseの場合、全てのデータ(1エポック分)を返すと反復を終える。
shuffle: bool型
Trueの場合、ランダムな順序でデータを返す。
Falseの場合、datasetと同じ順序で返す。
SerialIteratorの動作を確認する。
スクリプト
np.random.seed(0)
data = np.arange(3)
data = chainer.Variable(data)
ite = chainer.iterators.SerialIterator(data, batch_size=2,
repeat=True, shuffle=True)
for i in range(5):
print(ite.next())上のスクリプトでは、データの順序を固定するため、np.random.seed(0)としてNumPyの乱数シードを設定している。
0, 1, 2の3つの数字からなる配列をVariableオブジェクトとして、SerialIteratorにセットする。
バッチ数は2として、データを返す順序はランダムとする。
SerialIteratorオブジェクトiteのnext()メソッドを実行すると、バッチ数だけデータが返される。
実行結果
[variable(2), variable(1)]
[variable(0), variable(0)]
[variable(2), variable(1)]
[variable(0), variable(1)]
[variable(2), variable(2)]実行結果を見ると、Variableオブジェクトがbatch_size数だけリスト形式で返されている。
データ(0, 1, 2)を一通り返すと、同じリストであっても継続してデータを返している。
TupleDatasetによるデータセット作成 #
Iteratorクラスにセットするデータセットを用意する場合、TupleDatasetを用いると便利である。
chainer.datasets.TupleDataset(*datasets)datasetsは任意の数のデータ変数である。ただし、データは全て同じ長さ(行数)でなければならない。
TupleDatasetの主なメソッドは次の2つ。
getitem(index): indexで指定した要素をタプルで返す。
len: データの長さ(行数)を返す。
例えば、2つのNumPy配列d1, d2を引数として、次のようにTupleDatasetオブジェクトを作る。
d1 = np.array([[1, 2],
[3, 4],
[5, 6]], dtype=np.float32)
d2 = np.array([[7],
[9],
[8]], dtype=np.float32)
dataset = datasets.TupleDataset(d1, d2)
print(dataset.__len__())
for i in range(3):
print(dataset.__getitem__(i))実行結果
3
(array([1., 2.], dtype=float32), array([7.], dtype=float32))
(array([3., 4.], dtype=float32), array([9.], dtype=float32))
(array([5., 6.], dtype=float32), array([8.], dtype=float32))データの長さは3, また、__getitem__メソッドにより、d1, d2の要素が1行ずつ取り出されている。
次に、TupleDatasetオブジェクトをSerialIteratorにセットしてみる。バッチ数は2とする。
d1 = np.array([[1, 2],
[3, 4],
[5, 6]], dtype=np.float32)
d2 = np.array([[7],
[9],
[8]], dtype=np.float32)
data_set = datasets.TupleDataset(d1, d2)
ite = iterators.SerialIterator(data_set, batch_size=2,
repeat=True, shuffle=True)
for i in range(5):
print(ite.next())実行結果
[(array([5., 6.], dtype=float32), array([8.], dtype=float32)), (array([1., 2.], dtype=float32), array([7.], dtype=float32))]
[(array([3., 4.], dtype=float32), array([9.], dtype=float32)), (array([5., 6.], dtype=float32), array([8.], dtype=float32))]
[(array([1., 2.], dtype=float32), array([7.], dtype=float32)), (array([3., 4.], dtype=float32), array([9.], dtype=float32))]
[(array([3., 4.], dtype=float32), array([9.], dtype=float32)), (array([5., 6.], dtype=float32), array([8.], dtype=float32))]
[(array([1., 2.], dtype=float32), array([7.], dtype=float32)), (array([3., 4.], dtype=float32), array([9.], dtype=float32))]このように、各ite.next()毎に、d1とd2の各行がネストされたタプルで得られる。
ite.next()の結果をd1, d2毎にまとめるためには、chainer.dataset.concat_examples()を用いる。(評価関数にデータを与えるときに必要)
dataset.concat_examples(ite.next())実行結果
(array([[5., 6.],
[3., 4.]], dtype=float32),
array([[8.],
[9.]], dtype=float32))実装例 #
Iteratorを使った学習例を示す。前回の記事のスクリプトを改良した。
学習するデータの順序をランダムに入れ替える以外、前回と同じ学習条件である。 線形モデル y=x-5 を学習させる。 説明変数 x は0~9.9まで0.1刻みで100点とする。 また、教師データの目的変数には、平均0, 分散0.1の正規分布に従う信号をノイズとして加えた。 この教師データを100回反復させて学習させる(エポック数100)。 また、教師データを2点ずつ与えるバッチ処理を行う。
import numpy as np
import chainer
import chainer.links as L
import chainer.functions as F
from chainer import optimizers, Chain, dataset, datasets
import matplotlib.pyplot as plt
class MyChain(Chain):
def __init__(self):
super(MyChain, self).__init__()
with self.init_scope():
self.l1 = L.Linear(None, 3)
self.l2 = L.Linear(3, 1)
def __call__(self, x):
h = F.relu(self.l1(x))
return self.l2(h)
def lossfun(train_y, pred_y):
loss = F.mean_squared_error(train_y, pred_y)
return loss
np.random.seed(0)
batch_size = 2 # バッチ数
n_epoch = 100 # エポック数
model = MyChain()
optimizer = optimizers.SGD().setup(model)
x_data = np.arange(0, 10, 0.1, dtype=np.float32).reshape(-1,1) # 説明変数
y_data = x_data-5 + 0.1*np.random.randn(len(x_data)).reshape(-1,1)
y_data = y_data.astype(np.float32) # 目的変数
data_set = datasets.TupleDataset(x_data, y_data)
ite = chainer.iterators.SerialIterator(data_set, batch_size=batch_size,
repeat=True, shuffle=True)
pred_y_before = model(x_data) # 学習前の予測値
mean_err = [] # 平均予測誤差
for epoch in range(n_epoch):
err_temp = 0
for i in range(0, x_data.shape[0], batch_size):
batch = ite.next()
train_x, train_y = dataset.concat_examples(batch)
pred_y = model(train_x)
optimizer.update(lossfun, train_y, pred_y)
err_temp += F.mean_squared_error(train_y, pred_y).data*batch_size
mean_err += [err_temp/x_data.shape[0]]
pred_y_after = model(x_data) # 学習後の予測値
fig, ax = plt.subplots()
ax.plot(x_data, y_data, label="True values")
ax.plot(x_data, pred_y_before.data, label="Before learning")
ax.plot(x_data, pred_y_after.data, label="After learning")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.legend()
ax.grid()
plt.show()
fig, ax = plt.subplots()
ax.plot(mean_err)
ax.set_xlabel("Epoch")
ax.set_ylabel("Mean squared error")
ax.grid()
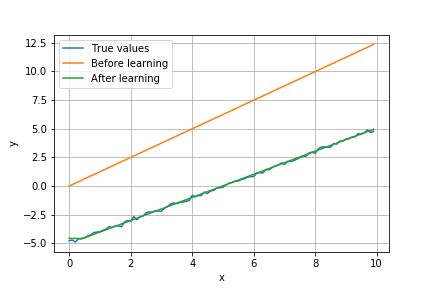
plt.show()学習前後のモデルの予測値は次のようになった(青が教師データ、黄色が学習前の予測値、緑が学習後の予測値)。
学習によって、予測値が教師データに近づいている。
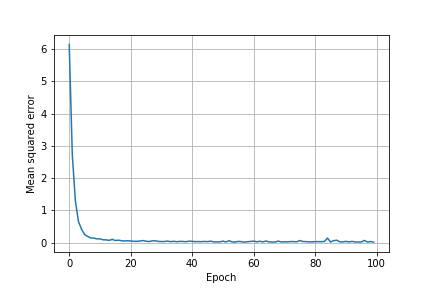
また、エポックごとの予測の二乗平均誤差は以下の通り。
データをシャッフルしなかった前回と比べ、誤差の減少が速くなっている。
参考リンク #
chainer.iterators.SerialIterator — Chainer 7.7.0 documentation
