はじめに #
KerasのステートフルRNNおよび、Kerasのコードについて解説する。 ステートフルRNNは、学習バッチ間で内部状態を保持するため、学習を高速化できる。
再帰型ニューラルネットワーク(RNN)は、時系列データや言語データなど、過去のデータに対して、何らかの依存性を持つデータを扱うことが出来る。 これは、RNNがレイヤの内部に隠れ変数を持つことで、過去の変数を記憶しているためである。 通常のRNNでは、学習バッチごとに隠れ変数はリセットされるが、ステートフルRNNでは隠れ変数を保持することで、学習を高速化できる。
Kerasには、単純なRNNであるSimpleRNNのほかに、LSTMやGRUといったRNNレイヤが実装されているが、これら3つのRNNレイヤは全てステートフルを利用できる。 なお、本記事では、Tensorflow統合版のKeras(tf.keras)を用いたが、単独版のKerasでもステートフルRNNを利用できる。
本記事では、以下の通りライブラリをインポートしていることを前提とする。
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN, GRU, LSTM
また、使用したコードは以下のGistにまとめている。 KerasでステートフルRNNを使ったサンプルコード · GitHub
環境 #
| ソフトウェア | バージョン |
|---|---|
| Python | 3.7.3 |
| NumPy | 1.16.2 |
| Pandas | 0.24.2 |
| sklearn | 0.20.3 |
| TensorFlow | 1.14.0 |
ステートフルRNN #
ステートフルRNNについて解説する。
単純なRNN(SimpleRNN)やLSTM, GRUといったRNNレイヤは、過去の変数を記憶するため、内部に変数を持っている。例として、SimpleRNNの概念を下図に示す。 時刻tにおけるSimpleRNNへの入力をx[t], 出力をo[t], 内部の隠れ状態をh[t]とする。このとき、h[t]は1ステップ前の隠れ状態h[t-1]を用いて、 h[t] = tanh( Vh[t-1] + Ux[t] ) と更新される。 ただし、V, Uは重み行列である。 また、出力o[t]は、次式で表される。 o[t] = f( Wh[t] ) ただし、Wは重み行列、fは活性化関数(ReLUやシグモイド関数など)である。
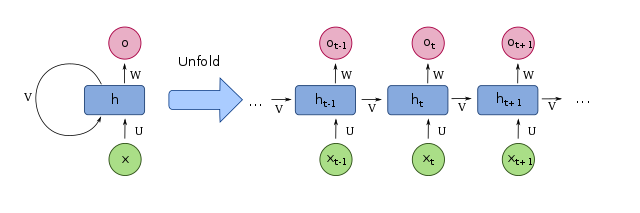
通常のRNNで内部状態が保持されるのは、連続したデータが与えられた期間のみである。データが途切れると、内部状態hはリセットされる。
ここで、次に与えられるデータが、前のデータに連続している場合を考える。 以下の図は、説明変数の数が1で、バッチサイズも1の場合である。一度に入力が3つ連続する場合、x[0]~x[2]が与えられた後に、x[3]~x[5]が与えられる(下図参照)。
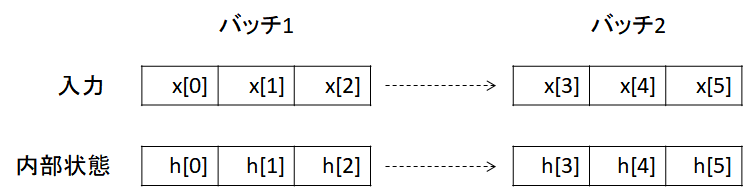
x[2]が与えられたとき、内部状態はh[2]であるが、その次にx[3]以降のデータが連続して与えられるのであれば、内部状態をリセットせずにそのまま引き継ぐ方が良い。 これは、以下の理由による。
- 内部状態を引き継ぐことで、学習(重み行列の更新)を高速化できる。
- バッチごとに内部状態をリセットする処理が不要になる。
このように、バッチ間で内部状態を保持するRNNをステートフルRNNという。 ステートフルRNNと区別するため、従来のバッチごとに内部状態をリセットするRNNをステートレス (stateless) RNNと呼ぶ。
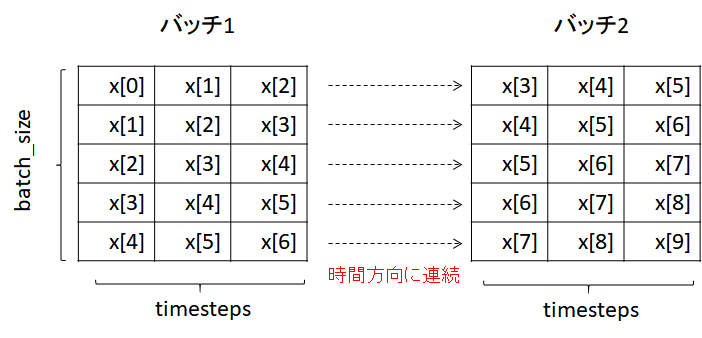
最後に、データがバッチで与えられる場合を考える。
下図ではバッチサイズを5とした。2番目のバッチで与えるデータは、それぞれ1番目のバッチで与えられたデータに対して、時間的に連続している必要がある。
KerasのステートフルRNN #
Kerasに実装されているステートフルRNNを使う場合には、以下の点に留意する。
- データの並びは時系列順とする(シャッフル禁止)
- エポック毎にモデルの内部状態をリセットする
- データの長さはバッチサイズの整数倍でなければならない 具体的なコードについては後述する。
対象データ #
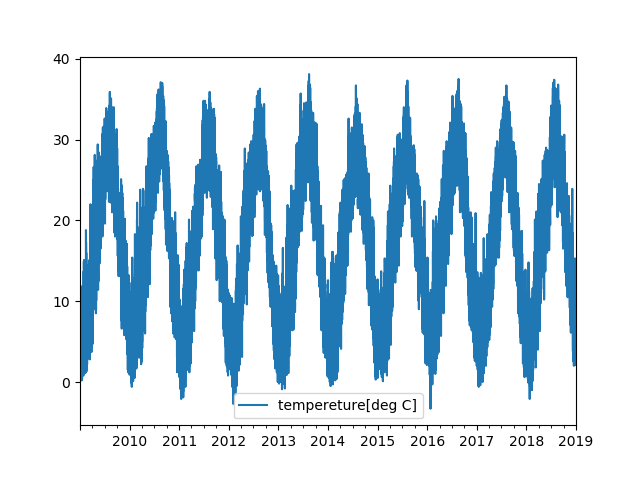
気温の予測を対象として、ステートフルRNNとステートレスRNNを比較する。 気温のデータは、気象庁から取得した2009年1月1日から2018年12月31日までの大阪の気温である。1時間周期であり、データ点数は87,648点になる。 Pythonで扱いやすいようにデータを加工し、CSV形式とした。以下のDropboxからダウンロードできる(Dropboxのアカウント登録は不要)。 Dropbox - osaka_temperature2009_2018.csv
グラフにすると以下の通り。ただし、欠損値があるので線形補間している。
df = pd.read_csv("osaka_temperature2009_2018.csv",
index_col=0, parse_dates=True)
df = df.interpolate(method="linear")
df.plot()
また、ニューラルネットワークで扱えるように、StandardScalerであらかじめ標準化しておく。
ss = StandardScaler()
std = ss.fit_transform(df)
std = std.astype(np.float32)
StandardScalerについては以下の記事を参考。 Scikit-learnでデータをスケール変換する
次に、説明変数と目的変数を定義する。 ここでは、過去6時間のデータを用いて、1時間後の気温を予測する。すなわち、timestepsは6とする。 バッチサイズに特に制約はないが、配列を変形するだけで簡単に学習データを作れるように、バッチサイズはtimestepsと同じ6とする。
※バッチサイズが6より大きいと、同じ時系列データが複数のバッチに含まれる。そのため、ジェネレータを使って、逐次的に学習データを生成した方がメモリ消費が少ない。RNN用のジェネレータについては以下の記事を参考。 Kerasの時系列予測でgeneratorを使って大容量データを扱う 前編 Kerasの時系列予測でgeneratorを使って大容量データを扱う 後編
timesteps = 6
batch_size = timesteps
x = np.empty([len(std)-timesteps, timesteps], dtype=np.float32)
y = np.empty(len(std)-timesteps, dtype=np.float32)
for i in range(len(x)):
x[i] = std[i:i+timesteps].T
y[i] = std[i+timesteps]
data_len = batch_size*int(len(x)/batch_size)
x = x[:data_len].reshape(data_len,timesteps,-1)
y = y[:data_len].reshape(data_len,-1)
また、ステートフルRNNでは内部状態が保存されるため、各バッチのサイズは同じでなければならない。そのため、最後のバッチでデータが余らないように、データの長さをbatch_sizeの整数倍としている。
モデルの定義・学習 #
用意した気温データを用いて、RNNを学習させる。 ステートレスとステートフルの2つのモデルを比較する。どちらのモデルも、1層目はノード数10のSimpleRNN, 2層目はノード数10の全結合(Dense)層とする。また、活性化関数はtanh, エポック数は3とする。
ステートレス #
ステートレスRNNのモデルを定義・実行する。 また、ステートフルモデルと条件をそろえるため、fit関数でshuffle=Falseとした。
actfunc = "tanh"
N_EPOCH = 3
model = Sequential()
model.add(SimpleRNN(10, activation=actfunc,
stateful=False,
input_shape=(timesteps, 1)))
model.add(Dense(10, activation=actfunc))
model.add(Dense(1))
model.compile(optimizer='RMSprop', loss='mean_squared_error')
history = model.fit(x, y, epochs=N_EPOCH, batch_size=batch_size,
verbose=1, shuffle=False)
実行結果:
Epoch 1/3
87642/87642 [==============================] - 33s 374us/sample - loss: 0.0112
Epoch 2/3
87642/87642 [==============================] - 32s 366us/sample - loss: 0.0063
Epoch 3/3
87642/87642 [==============================] - 31s 354us/sample - loss: 0.0062
ステートフル #
ステートフルRNNのモデルを定義・実行する。 SimpleRNNレイヤでstateful=Trueとすると、ステートフルになる。また、SimpleRNNとfitの両方でbatch_sizeを定義する。ステートフルモデルでは内部状態が自動でリセットされないため、エポック毎にmodel.reset_states()でリセットする。
model = Sequential()
model.add(SimpleRNN(10, activation=actfunc,
stateful=True,
input_shape=(timesteps, 1),
batch_size=batch_size))
model.add(Dense(10, activation=actfunc))
model.add(Dense(1))
model.compile(optimizer='RMSprop', loss='mean_squared_error')
for i in range(N_EPOCH):
history = model.fit(x, y, epochs=1, batch_size=batch_size, verbose=1, shuffle=False)
model.reset_states()
87642/87642 [==============================] - 30s 343us/sample - loss: 0.0074
87642/87642 [==============================] - 30s 337us/sample - loss: 0.0061
87642/87642 [==============================] - 30s 339us/sample - loss: 0.0061
ステートレスとステートフルを比較すると、ステートフルが1エポックの実行時間がやや短い。また、1エポック目の損失関数が小さくなっており、学習が速いことが分かる。
まとめ #
気温のデータを対象として、ステートフルRNNで学習を高速にできることを示した。
参考 #
気象庁 気象庁|過去の気象データ検索
大阪の気温データ(Dropbox) Dropbox - osaka_temperature2009_2018.csv
使用したコード(Gist) KerasでステートフルRNNを使ったサンプルコード · GitHub
